.svg)
AI 솔루션 문의하기



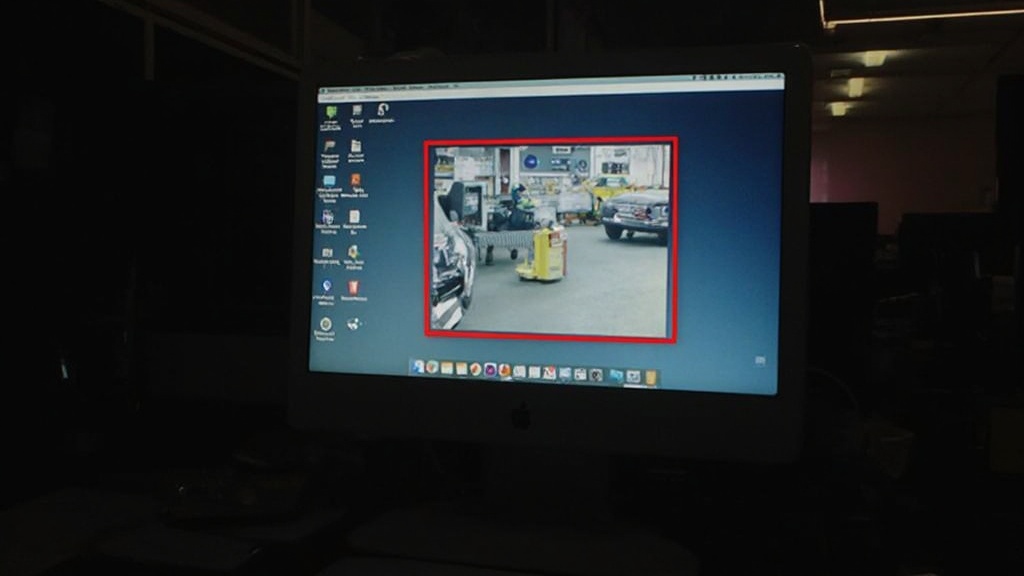
자율주행 데이터 라벨링의 두 가지 주요 방식은 Bounding Box와 Segmentation입니다. Bounding Box는 객체를 감싸는 최소 크기의 직사각형으로 표현합니다. 4개의 좌표(좌상단 x, 좌상단 y, 우하단 x, 우하단 y)로 간단히 정의됩니다. 이 방식은 매우 빠르고 간단해서, 대규모 데이터 라벨링에 적합합니다.
반면 Segmentation은 객체의 정확한 경계를 픽셀 단위로 그려냅니다. 객체의 실제 형태를 마스크(mask) 형태로 표현하므로, 훨씬 더 정교한 정보를 제공합니다. Bounding Box는 객체가 어디에 있는지만 말해주지만, Segmentation은 객체가 정확히 어디까지 차지하는지를 알려줍니다. 예를 들어, 보행자를 라벨링할 때, Bounding Box는 사람을 포함하는 직사각형을 그리지만, Segmentation은 사람의 실제 외곽선을 따라 그립니다.
▲ Bounding Box 장점: 라벨링 속도 빠름, 라벨링 비용 낮음, 간단한 인프라
▲ Bounding Box 한계: 객체 정확한 형태 미포함, 객체 간 오버랩 처리 어려움, 배경 정보 불포함
▲ 활용: 빠른 프로토타입, 실시간 처리 필요 시스템, 초기 모델 개발
Bounding Box의 가장 큰 장점은 라벨링 속도와 비용입니다. 사람이 객체의 좌상단과 우하단 좌표만 입력하면 되므로, Segmentation보다 훨씬 빠르게 라벨링할 수 있습니다. 또한 자동화 도구를 사용하여 반자동 라벨링도 쉽습니다. 따라서 수백만 개의 이미지를 라벨링할 때 경제적입니다. 하지만 한계도 명확합니다. Bounding Box는 객체의 정확한 형태를 무시합니다. 자동차를 라벨링할 때도, 복잡한 형태의 건설 장비를 라벨링할 때도, 동일하게 직사각형으로 표현되어서, 그 안의 배경 픽셀이 포함됩니다. 또한 두 개의 객체가 겹쳤을 때 정확히 구분하기 어렵습니다.
Segmentation은 객체의 정확한 경계를 픽셀 단위로 표현합니다. 보행자를 라벨링할 때 사람의 머리, 몸, 팔, 다리의 정확한 외곽선을 따라 마스크를 그립니다. 이 방식은 매우 정교하고 정확합니다. 자율주행 모델이 학습할 때, 정확한 객체 경계 정보를 받게 되어 더욱 정확한 판단을 할 수 있습니다. 예를 들어, 보행자의 팔이 튀어나온 부분까지 정확히 인식하면, 자동차가 안전 거리를 더 정확히 계산할 수 있습니다.
하지만 이 정교함은 비용이 높습니다. 라벨러가 마우스로 객체의 모든 픽셀 경계를 추적해야 하므로, 매우 시간이 걸립니다. Bounding Box 라벨링보다 3배에서 5배 이상의 시간과 비용이 필요할 수 있습니다. 또한 라벨러의 숙련도에 따라 품질 편차가 크게 납니다.

Segmentation 기술도 두 가지로 나뉩니다: Semantic Segmentation과 Instance Segmentation.
Semantic Segmentation은 각 픽셀을 클래스별로 분류합니다. 예를 들어, 도로 이미지에서 모든 픽셀을 "도로", "보행자", "차량", "건물" 등으로 분류합니다. 같은 클래스에 속하는 여러 객체를 구분하지 않습니다. 도로에 자동차 3대가 있으면 모두 같은 "자동차" 클래스로 처리됩니다.
반면 Instance Segmentation은 같은 클래스 내에서 개별 객체를 구분합니다. 도로의 자동차 3대를 "자동차1", "자동차2", "자동차3"으로 각각 라벨링합니다. 자율주행에서는 보통 Instance Segmentation이 더 유용합니다. 왜냐하면 자동차가 각 자동차의 정확한 위치와 크기를 알아야 충돌 회피를 정확히 계산할 수 있기 때문입니다. Semantic Segmentation만으로는 두 자동차 사이의 거리를 정확히 파악하기 어렵습니다.

Panoptic Segmentation은 Semantic Segmentation과 Instance Segmentation을 결합한 기술입니다. "Thing"(셀 수 있는 객체: 자동차, 보행자, 자전거)과 "Stuff"(셀 수 없는 배경: 도로, 하늘, 건물)를 모두 처리합니다. 각 픽셀에 클래스 레이블과 인스턴스 ID를 함께 할당합니다. 예를 들어, 도로 이미지의 각 픽셀이 "도로 1", "도로 2", "차량1", "차량2", "보행자1" 등으로 라벨링됩니다. 이 방식은 가장 포괄적인 장면 이해를 제공합니다. 자율주행 시스템이 배경(도로, 차선)과 객체(다른 차량, 보행자) 모두를 정확히 이해할 수 있습니다. 하지만 라벨링 복잡도가 매우 높고, 필요한 계산 자원도 많습니다. 또한 배경과 객체가 겹칠 때 충돌을 해결하는 방식도 정해야 합니다.
자율주행 기업들은 정확성과 비용의 균형을 맞춰 라벨링 방식을 선택합니다. 초기 프로토타입 개발 단계에서는 Bounding Box를 사용하여 빠르게 모델을 만듭니다. 개발 속도가 빠르고 비용이 낮기 때문입니다. 모델 성능이 어느 정도 확보되면 Instance Segmentation으로 업그레이드합니다. 더 정확한 경계 정보로 모델 성능을 향상시킵니다. 최종 상용화 단계에서는 Panoptic Segmentation 데이터로 완성도를 높입니다. 이렇게 단계적 접근을 하는 이유는, 모든 데이터를 Panoptic Segmentation으로 라벨링하면 비용이 감당 불가능할 수 있기 때문입니다.
예를 들어, 1000만 개의 이미지를 Panoptic Segmentation으로 라벨링하려면, 수십억 원대의 비용이 필요할 수 있습니다. 따라서 대부분의 자동차 회사는 핵심 시나리오(도시 중심부, 복잡한 교통)는 Segmentation으로, 단순한 고속도로는 Bounding Box로 라벨링합니다.

Bounding Box는 자동화가 매우 쉽습니다. 컴퓨터 비전 모델이 객체를 감지하고 자동으로 Bounding Box를 그릴 수 있습니다. 그 후 사람이 오류를 수정하는 반자동 라벨링 방식을 사용합니다. 이 방식은 라벨러의 작업량을 크게 줄입니다.
반면 Segmentation은 자동화가 어렵습니다. 객체의 정확한 경계는 매우 미묘한 부분(머리카락, 옷주름)까지 포함해야 하므로, 완전 자동화가 불가능에 가깝습니다. 따라서 Segmentation은 여전히 사람의 수작업에 크게 의존합니다.
최근에는 약한 감시 학습(Weakly Supervised Learning) 기술을 사용하여, Bounding Box로부터 자동으로 Segmentation을 생성하려는 시도가 있습니다. 예를 들어, Bounding Box와 프레임 내 위치 정보를 사용하여 대략적인 Segmentation을 자동으로 생성하고, 라벨러가 미세한 부분만 수정하는 방식입니다. 이 기술이 성숙하면 Segmentation의 라벨링 비용이 크게 절감될 것입니다.
모델의 성능은 라벨링 데이터의 품질에 직접 영향을 미칩니다. Bounding Box로 학습한 모델은 빠르지만 정확도가 낮습니다. 특히 객체의 정확한 위치와 크기를 파악해야 하는 작업(충돌 회피, 거리 측정)에서 오류가 증가합니다. Segmentation으로 학습한 모델은 정확도가 훨씬 높습니다. 객체의 정확한 경계를 학습하므로, 더 정확한 판단을 할 수 있습니다.
예를 들어, 비오는 날씨에 차선이 불명확할 때, 정확한 Segmentation 데이터로 학습한 모델은 차선을 더 정확히 인식합니다. 또한 Panoptic Segmentation 데이터는 배경과 객체를 동시에 이해하므로, 가장 복잡한 장면에서 최고의 성능을 발휘합니다. 다만 모델 크기도 커지고 계산량도 증가합니다. 실시간 처리 속도와 정확도 사이의 트레이드오프가 발생합니다.
자율주행 자동차는 매초 수십 번의 의사결정을 해야 하므로 실시간 처리가 필수입니다. Bounding Box를 사용한 모델은 가볍고 빨라서, 차량 내 embedded GPU에서 실시간 처리 가능합니다. 반면 Instance Segmentation 모델은 훨씬 무겁고 느립니다. 각 픽셀의 클래스와 인스턴스 ID를 계산해야 하므로, 계산량이 Bounding Box의 10배 이상 증가할 수 있습니다.
Panoptic Segmentation은 더욱 무겁습니다. 따라서 차량 내에서 Panoptic Segmentation을 완전히 구현하기는 어렵습니다. 대신 클라우드 서버에서 처리하거나, 모델 경량화 기술(모델 압축, 양자화)을 적용하여 차량 내에서 실행 가능하게 만듭니다. 이 과정에서 정확도 손실이 발생할 수 있습니다. 따라서 실시간 처리 요구사항과 정확도의 균형이 중요합니다.
Bounding Box 라벨링은 관리가 상대적으로 간단합니다. 좌표가 정확한지 몇 가지 규칙으로 자동 검증 가능합니다. 품질 관리 도구도 많이 존재합니다. 반면 Segmentation 라벨링은 품질 관리가 매우 어렵습니다. 두 명의 라벨러가 같은 이미지를 라벨링하면 완전히 다른 결과가 나올 수 있습니다. 물론 피크셀 단위의 정확도를 측정할 수는 있지만, 어느 정도까지가 수용 가능한 오류인지 정하기 어렵습니다.
따라서 대규모 Segmentation 라벨링 프로젝트에서는, 라벨러 교육, 품질 검증, 다중 라벨링(여러 사람이 같은 데이터를 라벨링) 등에 많은 비용을 투자합니다. 또한 라벨링 가이드도 매우 상세해야 합니다. "머리카락까지 정확히 그릴 것", "겹쳐진 부분은 위쪽 객체만 포함" 등의 규칙을 명확히 정의해야 합니다.
최근 기술 발전으로 Bounding Box와 Segmentation의 경계가 흐려지고 있습니다. 약한 감시 학습 기술이 발전하면서, Bounding Box 데이터로부터 Segmentation을 자동 생성하는 기술이 개선되고 있습니다. 또한 자동 라벨링 도구가 점점 정교해져서, 일부 Segmentation 작업을 반자동으로 처리 가능하게 되었습니다. 또한 "하이브리드 접근"이 주목받고 있습니다. 복잡한 객체(보행자)는 Segmentation으로, 단순한 객체(신호등)는 Bounding Box로 라벨링하는 식입니다. 또한 도시의 복잡한 지역은 Instance Segmentation으로, 단순한 고속도로는 Semantic Segmentation으로 라벨링합니다. 이렇게 문맥과 필요에 따라 라벨링 방식을 달리하면, 정확도와 비용의 균형을 맞출 수 있습니다.
3D Segmentation 기술도 발전하고 있어서, 앞으로는 2D Bounding Box 대신 3D 형태를 정확히 캡처하는 기술이 표준이 될 가능성도 있습니다.





.svg)
.svg)


