.svg)
AI 솔루션 문의하기



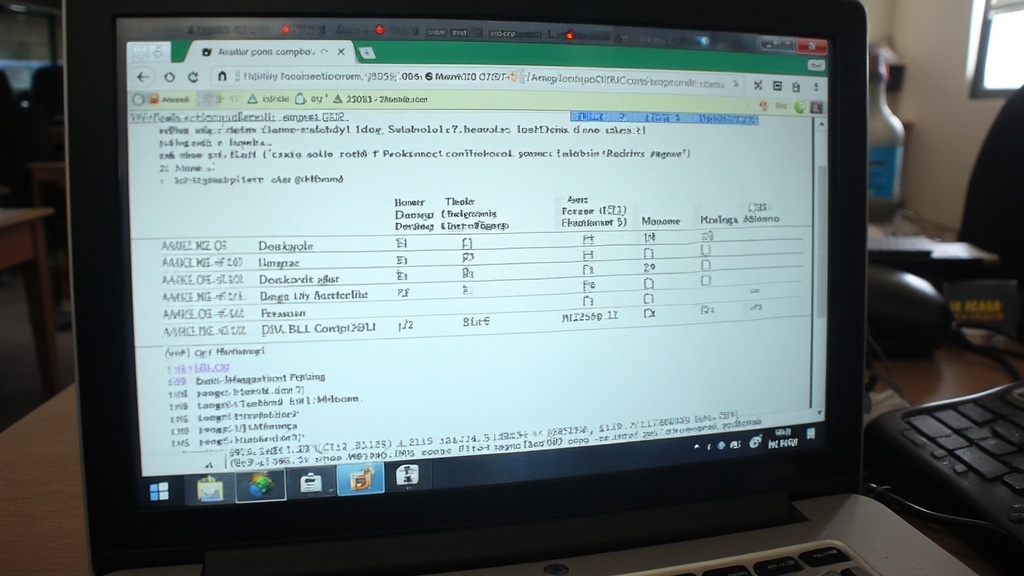
표 데이터를 정확하게 추출하기 위해서는 해당 표가 문서의 어느 위치에 어떤 의도로 배치되었는지 파악하는 것이 우선입니다. AI는 텍스트, 이미지, 도표 등이 혼합된 비정형 문서에서 시각적 특징을 분석하여 표가 시작되고 끝나는 지점을 논리적으로 정의합니다. 이는 단순한 좌표 기반의 인식을 넘어 문서의 제목, 본문, 캡션과의 관계를 분석함으로써 데이터가 가진 배경 지식을 보존하고 추출 효율을 극대화하는 기초 공정으로 작동합니다.
컴퓨터 비전 알고리즘은 문서 내의 선, 여백, 텍스트의 정렬 상태를 학습하여 표의 외부 경계를 확정합니다. 특히 표 주변에 복잡한 배경 문양이나 로고가 섞여 있는 경우에도 데이터가 포함된 핵심 구역만을 핀셋으로 집어내듯 정교하게 분리해냅니다. 이 단계에서 확보된 영역 정보는 이후 진행될 셀 분할의 정확도를 결정짓는 이정표가 되며, 다양한 문서 양식에서도 흔들림 없는 성능을 유지할 수 있는 기반이 됩니다.

표 영역 내부에서 데이터가 담긴 최소 단위인 셀의 경계를 픽셀 단위로 정밀하게 계산하여 데이터 간 침범을 원천 차단합니다.
딥러닝 모델은 물리적인 테두리뿐만 아니라 텍스트 간의 간격과 흐름을 읽어내어 각 셀의 공간적 범위를 확정하며, 복잡한 격자 구조에서도 데이터의 독립성을 완벽하게 보장합니다.
분리된 개별 셀들이 어떤 행과 열에 속하는지 논리적 지도를 구성합니다. 인공지능은 각 셀의 좌표와 상대적 위치를 분석하여 수평적 관계인 행과 수직적 관계인 열의 인덱스를 부여합니다. 이 과정은 표의 시각적 형태를 데이터베이스가 이해할 수 있는 매트릭스 구조로 변환하는 핵심 절차이며, 이를 통해 사용자는 추출된 데이터만으로도 원본 표의 전체적인 구성과 수치 간의 관계를 한눈에 파악할 수 있게 됩니다.

격자 구조가 완성되면 각 셀 내부에 담긴 텍스트 정보를 디지털 문자로 치환하는 본격적인 OCR 공정을 진행합니다. 폰트의 종류, 크기, 훼손 상태에 관계없이 인공지능이 문자의 획과 특징을 분석하여 정확한 텍스트 정보를 추출해냅니다. 특히 표 내부의 아주 작은 숫자나 특수 기호까지 놓치지 않고 판독하며, 인식된 데이터는 각 셀의 위치 정보와 결합하여 디지털 자산으로서의 가치를 갖추게 됩니다.
실제 업무 문서에는 가로선이나 세로선이 생략된 투명한 형태의 표가 빈번하게 등장합니다. AI는 눈에 보이는 선에 의존하지 않고 데이터 간의 수직 및 수평 정렬 상태를 추론하여 보이지 않는 구조를 재구성합니다. 반복되는 데이터 패턴과 일정한 간격을 학습한 모델이 투명한 격자망을 투영하듯 구조를 파악해내며, 이를 통해 선이 없는 유연한 디자인의 표에서도 데이터 누락 없이 완벽한 정형화를 구현합니다.

가로나 세로로 합쳐진 병합 셀은 표 해석의 난도를 높이는 주요 원인입니다. AI 솔루션은 병합된 셀이 어떤 하위 데이터들을 포함하고 있는지 논리적 계층 구조를 분석하여 HTML의 colspan이나 rowspan과 같은 속성으로 재현합니다. 상위 카테고리와 세부 항목 사이의 종속 관계를 유지한 상태로 정보를 추출하기 때문에, 변환 이후에도 표가 가진 고유의 의미 체계와 데이터 간의 위계 질서가 변함없이 유지됩니다.
추출된 데이터의 정확성을 보장하기 위해 표 내부에 포함된 수치 간의 산술적 관계를 검토합니다. 예를 들어 특정 열의 합계가 상단 데이터들의 총합과 일치하는지 AI가 직접 계산해보고, 불일치가 발견되면 해당 구역을 재인식 대상으로 분류합니다. 이러한 자가 검증 프로세스는 사람이 일일이 대조하지 않아도 데이터의 신뢰도를 일정 수준 이상으로 보장하며, 대량의 수치 데이터를 다루는 금융이나 회계 분야에서 필수적인 보안 장치로 작동합니다.

글로벌 비즈니스 환경을 고려하여 한글, 영어뿐만 아니라 전 세계 다양한 언어와 통화 기호, 전문 용어를 동시에 지원합니다. 각 언어별 폰트 특성과 문장 구조를 학습한 모델은 혼용된 언어 사이에서도 정확한 데이터를 뽑아내며, 화학식이나 수학 공식 같은 특수 기호도 문맥에 맞춰 인식합니다. 이는 전 세계 지사에서 들어오는 다양한 서식의 문서를 하나의 시스템에서 통합적으로 관리할 수 있는 기술적 범용성을 제공합니다.

모든 분석이 완료된 데이터는 JSON, XML, CSV 등 시스템 친화적인 형식으로 출력됩니다. 각 데이터가 가진 논리적 인덱스와 속성 정보를 보존하며 출력하기 때문에, 기업 내부의 데이터베이스나 기존 업무 워크플로우와 즉각적으로 연동할 수 있습니다. 수작업에 의존하던 데이터 입력 공정을 완전히 자동화함으로써, 데이터 수집에서 활용까지 걸리는 시간을 혁신적으로 단축하고 업무 효율성을 극대화합니다.
다양한 양식의 표를 처리하며 축적된 데이터를 바탕으로 알고리즘의 인식 성능을 지속적으로 향상시킵니다. 사용자가 결과물을 미세하게 교정한 이력을 학습 데이터로 다시 활용하여, 시간이 지날수록 해당 기업 고유의 특수한 문서 서식이나 난해한 표 구조에 최적화된 높은 수준의 재현 능력을 제공합니다. 인공지능은 반복되는 패턴을 스스로 학습하며 장기적으로는 어떠한 변형된 양식이 입력되더라도 오차 없는 변환 성능을 유지합니다.





.svg)
.svg)


